A Companion to the History of the Book (9 page)
Read A Companion to the History of the Book Online
Authors: Simon Eliot,Jonathan Rose

Measures of central tendency are key to understanding what was usual practice and what was exceptional. They allow for comparison and evaluation of, for example, the average (or
mean
) print run of a Bible in 1647 and 1679, or the most frequently ordered print run (modal) by a publisher in the 1880s – which turned out to be a thousand (Weedon 2003). Once central measurements have been made, it is essential to record the level of deviation from them.
The most common statistical method used by book historians is frequency distribution. One example is the South African
Production Trends Database
established by the Information Science Department at the University of Pretoria in 2001 using data from the
South African National Bibliography
(SANB), augmented and verified by other sources, such as records obtained from libraries, literary museums, and publishers’ catalogues and price lists. They have also added data from publishers’ archives and bibliographical information from the books themselves. The SANB is primarily a tool for librarians, which limits its usefulness as a source for book publishing statistics and production trends. Nevertheless, Francis Galloway (2005) has been able to analyze these data and produce tables of ISBN production by language from 1990 to 1998, concluding:
There was a marked change in the language composition of title output in the 1990s. English grew from 48% of the annual production in 1990 to 58% of the annual production in 1998; Afrikaans declined from 28% to 21% of the annual production in these years; and the combined output in the nine African languages grew from 8% to 11%.
Trends and fluctuations require the data to be analyzed over a specified period of time: correlation requires the analysis of how different variables affected, for example, the geographical spread of books. Using bibliometric methods on the sequence of Short Title Catalogues from the
Incunable Short Title Catalogue
(ISTC) to the
Nineteenth Century Short Title Catalogue
(NSTC), book historians have been able to determine “the origins and nature of the printed books imported into England and Scotland in the late fifteenth and early sixteenth centuries, and of annual book production in England, Scotland and Ireland between 1475 and 1700” amongst other things (Eliot 2002: 284). For example, in 1992 Maureen Bell and John Barnard published their preliminary count of the titles in the STC from 1475 to 1640, vividly illustrating the increase in titles over the period with a frequency analysis exploring the fluctuations of continental books in the STC as well as the significance of British cities as centers of publication. This was done before the machine-readable version of the STC was available from the British Library. Revised statistics were later published in
The Cambridge History of the Book in Britain
, volume 4:
1557–1695
(Barnard and McKenzie 2002). Computers make statistical analysis easier and sometimes aid the gathering of the data, but rarely make the answers clearer. Bell and Barnard’s work shows how a simple count can give us a clearer view of the topography of the publishing landscape.
Whatever method is employed it needs to be faithful to the original data and alert to the reasons for its original collection. Nevertheless, data collected for one purpose can often be used by the historian for quite a different one. Take, for example, the history of company records. Cyprian Blagden (1960) was able to illustrate how the Stationers’ Company built up new capital during the eighteenth century by small increases in the number of shares and to demonstrate how this became an unsustainable business practice when, after 1796, the cash was used to pay tax. Half a century later, printing, newspaper, and publishing companies were forced to keep good accounts by law, and this makes it easier to examine the workings and profitability of their business. One good example from the United States is Michael Winship’s (1995) account of the firm of Ticknor and Fields. His insights into the practices of mid-nineteenth-century American literary publishing are sharpened by statistics showing the firm’s output, sales, and production costs extracted from the accounts of the time. Later still, the more sophisticated management systems in use in the latter half of the twentieth century make it appropriate for historians to seek to quantify the intellectual capital of a firm. Data on the length of product development, the extent of revisions and corrections, and the number and value of copyrights owned are also recorded in this period (
Bookseller
1995; O’Donnell et al. 2006).
Common Limitations to Quantitative Analysis
The chief problem for the book historian wanting to use quantitative methods is the quality of the data. The sample is often small, selected for preservation or significance rather than at random, and the information on how the data were compiled or what they measured is sometimes lost. Primitive administration, book-keeping, and reporting procedures have created pseudo-statistics in the historical record; even published government figures are not necessarily clear or reliable. Nevertheless, they are all the book historian has and, though we may distrust them, we can also offer a guide to how they should be interpreted through stated degrees of uncertainty , ranges of confidence, and levels of significance. There are standard measures for error and deviation, correlation and confidence which give this information.
Where there is a wealth of historical data, quantitative descriptions seek to find trends and look for patterns. Categorization is a useful tool to group together similarities whether through the putting together of books by genre, authors by social background, or publishers by turnover. This aids the analysis of broader historical trends which could not be otherwise understood. However, statistical descriptions can retain evidence of the diversity in the data by measurements of variance and error. And unlike the consciously – or unconsciously – selective gathering of evidence in qualitative research, the means of gathering and interpreting patterns in quantitative data are made explicit with clear statements as to the levels of divergence from the patterns found.
Variance may not be recorded in the historical data series, though in some cases it can be partially retrieved. Take, for example, the average wage of a compositor in 1866 in Mitchell’s (1988) statistics and in Howe and Waite’s
The London Society of Compositors
(1948). Mitchell’s figures are largely derived from Bowley’s (1900) analysis of the
Reports
of the Scottish Typographical Society. Going back to his sources, the book historian can see that the figures for 1866 range from 18s 3d to 28s 3d per week. The London Society of Compositors’ report in 1866 cited a range from 21s to 30s. The wages in their sample varied by region: yet the variation of 10s and 9s is comparable, and though there is not enough data to calculate standard deviation, this knowledge aids the interpretation of both authors’ average wage figure.
Another frequent problem is comparability between two sets of figures. For example, it is tempting to compare Alex Hamilton’s annual round-up of the top hundred British fastsellers with the Public Lending Right statistics on the most popularly borrowed books from libraries to see if there are related trends in borrowing and buying books (see Hamilton 2005). Hamilton lists books published in the calendar year with their country of origin, genre, recommended retail price, sales – home and export – and a simple calculation of their monetary value. The list ranks these in order, starting with the title with greatest sales. It offers quantitative information on the year’s activity in the high-turnover fiction market. The Public Lending Right (PLR) issues statistics on the most borrowed authors from a sample of public libraries in the UK. Among other measures, their charts show the most popular genres, the top children’s writers, and the most borrowed authors of classics. The statistics run from July to June, which makes direct comparison awkward but possible as both Hamilton’s and the PLR’s statistics have been published for more than two decades. The subject categories, however, are not compatible as they reflect the difference between the Dewey subject classification system and publishers’ genre labels. What emerges from this study is not so much the presence of comparable trends as evidence for the influence of other media, particularly of film releases, on the borrowing and sale of specific titles.
Gaye Tuchman and Nina E. Fortin (1989), in their study of novelists, publishers, and social change, observed that “[s]ampling problems often tell researchers about the topic they are studying.” They asked the question: were manuscripts by women authors as likely to be accepted as those by men in Victorian Britain? One of their sources was the record of the submission of manuscripts to the publisher Macmillan. In the appendix, Tuchman outlined two problems with the approach: first, the number of submissions per year increased over the period, and, secondly, the submission of manuscripts was seasonal, more manuscripts were received on some topics in some months:
To draw quickly a sufficiently large sample, Tuchman would have had either to sample (1) every “xth” manuscript from November 1866 through 1917, (2) the first 350 manuscripts in systematically selected years, or (3) every manuscript in specified entire years enlarging the number of years sampled when in the chosen year Macmillan received relatively few submissions, as occurred in 1867 and 1877. The first method would have overrepresented the later decades; the second might have overrepresented some months. So Tuchman chose the third method. (Tuchman and Fortin 1989: 219)
The authors supported their thesis with quantitative evidence from numbers of submissions (percentage accepted, rejected, and published), and the qualitative judgments of reviewers on women’s and men’s fiction. They also used the nineteenth-century edition of
The Dictionary of National Biography
as a source of women writers. This is more problematical as the entries were selected by the editors, who applied their own criteria to determine what made a person distinguished enough to be included. Thus, any sample of these entries is already skewed by the editors’ choice. Tuchman and Fortin wanted to examine the attitudes to women writers in comparison with their male counterparts, and this process of selection was one which, they concluded, reflected the “shift in gender concentration of novelists.” In addition, coding the entries with a customized “fame index” introduced a further subjective element derived, in this case, from the research team who made efforts to ensure that this was consistently applied. Coding qualitative data for quantitative use is a recognized practice in statistics for social sciences and can be a useful tool. However, once qualitative values are brought into quantitative descriptions, readers have to judge the rigor of the researchers’ methods – in this case the customized “fame index” and its application – for themselves. As with much statistical analysis, there is a tendency to discard things that do not fit the pattern. A clear statement of how the statistical exercise was conducted and monitored is vital. In this case, Tuchman and Fortin were concerned with the “edging out” of women novelists through the professionalization of the field, and they used their quantitative data to support their thesis, stating: “Before 1840 at least half of all novelists were women; by 1917 most high-culture novelists were men” (Tuchman and Fortin 1989 : 7 ) . Tuchman and Fortin’s ideologically motivated work uses methods widely accepted in the social sciences, but care must be taken when applied to historical data.
Understanding Trends with Time Series
Most questions arising in book history contain an element of change though time. Where data are ordered chronologically, time-series analysis methods can be used. These methods are designed to help separate the different possible influences on the series so that we can estimate the importance of each. One simple way of showing year-by-year changes is to use ratios and indices. For instance, it might be useful to know how the number of titles published – as recorded in the STC – grew in the decades following the 1560s (see
table 3.1
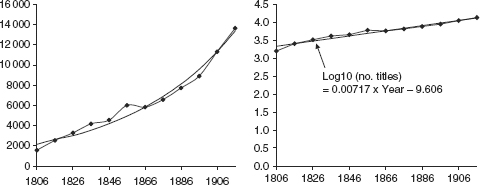
). The raw figures show that between 1560 and 1600 the number of titles more than doubled. By using 1560 as the index figure, we can see that, in these forty years, the number of titles in fact increased by 133.2 percent. Plot the data and the increase looks linear. The rate of growth, should you want to calculate it, is 1.72 percent per year, but this is hardly necessary. However, a plot of the number of titles published in the nineteenth century has a curvilinear form indicating exponential growth (
figure 3.1
). When plotted on a logarithmic scale, the trend is apparent, and we can show that the rate of growth published was 1.66 percent per year over the century.
Table 3.1
Growth in number of titles published 1560–1600, as recorded in the STC
Source
: Bell and Barnard (1992)
| Decade | Titles published | Percentage of 1560 total |
| 1560 | 1,392 | 100.0 |
| 1570 | 1,908 | 137.1 |
| 1580 | 2,373 | 170.5 |
| 1590 | 2,549 | 183.1 |
| 1600 | 3,246 | 233.2 |
Figure 3.1
Number of titles published in nineteenth-century Britain. Data from A. Weedon,
Victorian Publishing: The Economics of Book Production for the Mass Market 1836–1916
, 2003.