Pro Puppet (4 page)
Authors: Jeffrey McCune James Turnbull

About the Technical Reviewer
 |  Jes Fraser Jes Fraseris a solutions consultant from New Zealand specializing in Linux and Puppet in the Enterprise. She enjoys singing, playing the piano, and of course, writing. |
Thanks are owed to the following people for input and insight into the project:
Dan Bode
Luke Kanies
Nigel Kersten
Dennis Matotek
Hal Newton
R.I. Pienaar
Trevor Vaughan
All of the team at Puppet Labs who continue to make Puppet cool
James Turnbull
“ssh in a for loop is not a solution” – Luke Kanies, Puppet developer
The lives of system administrators and operations staff often revolve around a series of repetitive tasks: configuring hosts, creating users, and managing applications, daemons, and services. Often these tasks are repeated many times in the life cycle of one host, from building to decommissioning, and as new configuration is added or corrected for error or entropy.
The usual response to these repetitive tasks is to try to automate them with scripts and tools. This leads to the development of custom-built scripts and applications. In my first role as a systems administrator, I remember creating a collection of Control Language (CL) and Rexx scripts that I subsequently used to manage and operate a variety of infrastructure. The scripts were complex, poorly documented and completely customized to my environment.
My experience is not unique, and this sort of development is a common response to the desire to make life easier, automate boring, manual tasks and give you a few more minutes in the day for the more interesting projects and tasks (or to get to the pub earlier).
Very few of the scripts developed in this ad hoc manner are ever published, documented, or reused. Indeed, copyright for most custom material rests with the operator or system administrator's organization and is usually left behind when they move on. This leads to the same tool being developed over and over again. Sometimes they are even developed over and over again in the same company if previous incarnations don't suit a new incumbent (or occasionally, if they are indecipherable to a new incumbent!).
These custom scripts and applications rarely scale to suit large environments, and they often have issues of stability, flexibility, and functionality. In multi-platform environments, such scripts also tend to suit only one target platform, resulting in situations such as the need to create a user creation script for BSD, another one for Linux, and still another for Solaris. This increases the time and effort required to develop and maintain the very tools you are hoping to use to reduce administrative efforts.
Other approaches include the purchase of operations and configuration management tools like HP's Opsware, BMC's CONTROL-M, IBM's Tivoli suite, and CA's Unicenter products. But commercial tools generally suffer from two key issues: price and flexibility. Price, especially, can quickly become an issue: The more platforms and hosts that you are managing, the greater the price. In large environments, licensing for such tools can run to millions of dollars.
Flexibility is also a key concern. Commercial tools are usually closed source and are limited to the features available to them, meaning that if you want to extend them to do something custom or specific to your environment, you need to request a new feature, potentially with a waiting period and associated cost. Given the huge varieties of deployments, platforms, configurations and applications in organizations, it is rare to discover any tool that provides the ability to completely customize to suit your environment.
There is an alternative to both in-house development and commercial products: Free and Open Source Software (FOSS). Free and open source configuration management tools offer two key benefits for organizations:
- They are open and extensible.
- They are free!
With FOSS products, the tool's source code is at your fingertips, allowing you to develop your own enhancements or adjustments. You don't need to wait for the vendor to implement the required functionality or pay for new features or changes. You are also part of a community of users and developers who share a vision for the development of the tool. You and your organization can in turn contribute to that vision. In combination, you can shape the direction of the tools you are using, giving you a more flexible outcome for your organization.
The price tag is another important consideration for acquisition of any tool. With free and open source software, it isn't an issue. You don't pay anything for the software, and you get the source code with it.
Of course, we all know there is no such thing as a free lunch, so what's the catch? Well unlike commercial software, open source software doesn't come with any guaranteed support. This is not to say there is no support available: Many open source tools have large and active communities where members answer questions and provide assistance via mechanisms like email lists, forums, Wikis and IRC.
Note
Many open source tools, including Puppet, also have organizations that provide commercial editions or support for these tools. For full disclosure, both the author James Turnbull and co-author Jeff McCune work at Puppet Labs, the organization that supports the development of Puppet.
Puppet (http://www.puppetlabs.com/puppet) is a reaction to these gaps in the tools available to SysAdmins, Operators and Developers. It is designed to make their lives easier by making infrastructure easy, simple and cheap to manage. This book will introduce you to Puppet, an open source configuration management tool, and take you through installation, configuration and integration of Puppet into your environment.

Puppet is an open source framework and toolset for managing the configuration of computer systems. In this book, we’re going to look at how you can use Puppet to manage your configuration. As the book progresses, we’ll introduce Puppet’s features and then show you how to integrate Puppet into your provisioning and management lifecycle. To do this, we’ll take you through configuring a real-world scenario that we’ll introduce in
Chapter 2
.
In this chapter, we start with a quick overview of Puppet, what it is, how it works, and which release to use, and then we show you how to install Puppet and its inventory tool, Facter. We show you how to install it on Red Hat, Debian, Ubuntu, Solaris, Microsoft Windows, and via a Ruby gem. We’ll then configure it and show you how create your first configuration items. We’ll also introduce you to the concept of “modules,” Puppet’s way of collecting and managing bundles of configuration data. We’ll then show you how to apply one of these modules to a host using the Puppet agent.
Puppet is Ruby-based, licensed as GPLv2 and can run in either client-server or stand-alone modes. Puppet is principally developed by Luke Kanies and his company, Puppet Labs (formerly Reductive Labs). Kanies has been involved with Unix and systems administration since 1997 and developed Puppet from that experience. Unsatisfied with existing configuration management tools, Kanies began working with tool development in 2001 and in 2005 he founded Puppet Labs, an open source development house focused on automation tools. Shortly after this, Puppet Labs released their flagship product, Puppet.
Puppet can be used to manage configuration on UNIX (including OSX) and Linux platforms, and recently Microsoft Windows platforms as well. Puppet is often used to manage a host throughout its lifecycle: from initial build and installation, to upgrades, maintenance, and finally to end-of-life, when you move services elsewhere. Puppet is designed to continuously interact with your hosts, unlike provisioning tools which build your hosts and leave them unmanaged.
Puppet has a simple operating model that is easy to understand and implement. The model is made up of three components:
- Deployment
- Configuration Language and Resource Abstraction Layer
- Transactional Layer
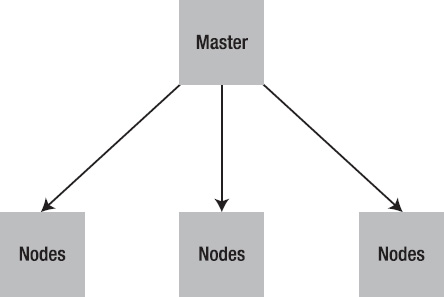
Figure 1-1.
The Puppet model
Puppet is usually deployed in a simple client-server model (
Figure 1-2
). The server is called a “Puppet master”, the Puppet client software is called an agent and the host itself is defined as a node.
The Puppet master runs as a daemon on a host and contains the configuration required for your environment. The Puppet agents connect to the Puppet master via an encrypted and authenticated connection using standard SSL, and retrieve or “pull” any configuration to be applied.
Importantly, if the Puppet agent has no configuration available or already has the required configuration then Puppet will do nothing. This means that Puppet will only make changes to your environment if they are required. The whole process is called a configuration run.
Each agent can run Puppet as a daemon via a mechanism such as cron, or the connection can be manually triggered. The usual practice is to run Puppet as a daemon and have it periodically check with the master to confirm that its configuration is up-to-date or to retrieve any new configuration. However, many people find being able to trigger Puppet via a mechanism such as cron, or manually, better suits their needs. By default, the Puppet agent will check the master for new or changed configuration once every 30 minutes. You can configure this period to suit your environment.
Figure 1-2.
Puppet client-server model
Other deployment models also exist. For example, Puppet can also run in a stand-alone mode where no Puppet master is required. Configuration is installed locally on the host and thepuppetbinary is run to execute and apply that configuration. We discuss this mode later in the book.
Puppet uses a declarative language to define your configuration items, which Puppet calls “resources.” This declarative nature creates an important distinction between Puppet and many other configuration tools. A declarative language makes statements about the state of your configuration - for example, it declares that a package should be installed or a service should be started.
Most configuration tools, such as a shell or Perl script, are imperative or procedural. They describe HOW things should be done rather than the desired end state - for example, most custom scripts used to manage configuration would be considered imperative.
This means Puppet users just declare what the state of their hosts should be: what packages should be installed, what services should be running, etc. With Puppet, the system administrator doesn’t care HOW this state is achieved – that’s Puppet’s problem. Instead, we abstract our host’s configuration into resources.
What does this declarative language mean in real terms? Let’s look at a simple example. We have an environment with Red Hat Enterprise Linux, Ubuntu, and Solaris hosts and we want to install thevimapplication on all our hosts. To do this manually, we’d need to write a script that does the following:
- Connects to the required hosts (including handling passwords or keys)
- Checks to see if
vimis installed - If not, uses the appropriate command for each platform to install vim, for example on Red Hat the
yumcommand and on Ubuntu theapt-getcommand - Potentially reports the results of this action to ensure completion and success
Note
This would become even more complicated if you wanted to upgrade vim (if it was already installed) or apply a particular version of vim.
Puppet approaches this process quite differently. In Puppet, we define a configuration resource for thevimpackage. Each resource is made up of a
type
(what sort of resource is being managed: packages, services, or cron jobs), a
title
(the name of the resource), and a series of
attributes
(values that specify the state of the resource - for example, whether a service is started or stopped).
You can see an example of a resource in
Listing 1-1
.
Listing 1-1.
A Puppet Resource
package { "vim":
ensure => present,
}
The resource in
Listing 1-1
specifies that a package calledvimshould be installed. It is constructed like:
type { title:
attribute => value,
}
In
Listing 1-1
, the resource type is thepackagetype. Puppet comes with a number of resource types by default, including types to manage files, services, packages, and cron jobs, among others.
Note
You can see a full list of the types Puppet can currently manage (and their attributes) athttp://docs.puppetlabs.com/references/stable/type.html. You can also extend Puppet to support additional resource types, as we’ll discuss in
Chapter 10
.
Next is the title of the resource, here the name of the package we want to install,vim. The type and title of the resource can be combined together to allow Puppet to create a reference to the resource. For example, our resource would be calledPackage["vim"]. We’ll see this a lot more in later chapters when we build relationships between resources, allowing us to create structure in our configuration, for example installing a package before starting its associated service.
Lastly, we’ve specified a single attribute,ensure, with a value ofpresent. Attributes tell Puppet about the required state of our configuration resource. Each type has a series of attributes available to configure it. Here theensureattribute specifies the state of the package: installed, uninstalled, etc. Thepresentvalue tells Puppet we want to install the package. To uninstall the package we would change the value of this attribute toabsent.
With our resource created, Puppet takes care of the details of how to manage that resource when our agents connect. Puppet handles the “how” by knowing how different platforms and operating systems manage certain types of resources. Each type has a number of “providers.” A provider contains the “how” of managing packages using a particular package management tool. For the package type, for example, for there are more than 20 providers covering a variety of tools includingyum,aptitude,pkgadd,ports, andemerge.
When an agent connects, Puppet uses a tool called “Facter” to return information about that agent, including what operating system it is running. Puppet then chooses the appropriate package provider for that operating system and uses that provider to check if thevimpackage is installed. For example, on Red Hat it would executeyum, on Ubuntu it would executeaptitude, and on Solaris it would use thepkgcommand. If the package is not installed, then Puppet will install it. If the package is already installed, Puppet does nothing.