The Rise and Fall of Modern Medicine (39 page)
Read The Rise and Fall of Modern Medicine Online
Authors: James Le Fanu

Almost daily the newspapers trumpet reports of the triumphs of The New Genetics. A selection of headlines from 1997 reads: âGene Find Gives Insight into Brittle Bones', âScientists Find Genes to Combat Cancer', âScientists Find Secret of Ageing', âGene Therapy Offers Hope to Victims of Arthritis', âHope of Skin Disease Cure as Gene Found', âCell Growth Gene Offers Prospect of Cancer Cure', âResearchers Encouraged by Fibrosis Gene Trial', âFour Genes Linked to Child Diabetes', âGene Transplants to Fight Anaemia', and so on. Even allowing for a certain amount of hyperbole on the part of the headline writers, there is a powerful impression that something really important is happening, though the frequent use of terms like âhope' and âprospect' and âclue' suggest it has not quite happened yet. And will it? The validity â or otherwise â for the claim that The New Genetics âpromises unprecedented opportunities' is obviously central to any evaluation of the history of post-war medicine, but the science involved is so arcane it is virtually impossible for anyone other than those directly involved to
understand precisely where it is going. The protagonists will naturally wish to âtalk up' the significance of what they are doing, while, for everyone else, the belief in its potential might simply rest on the assumption that so complex a matter
must
be important. The only way to try and come to a balanced judgement is to trace the evolution of the principal ideas over the last twenty-five years and then examine the record of its three practical applications to medicine: Genetic Engineering as a method of developing new drugs; Genetic Screening as a means of eradicating inherited disease; and Gene Therapy for the correction of genetic defects.
We begin with a preamble describing how the genes work, elucidated for greater clarity by reference to the schematic diagram on page 314. This starts in 1953, when James Watson and Francis Crick famously discovered the structure of DNA to be a spiral staircase (or double helix).
2
The two outer âbanisters' of the staircase are made up of two strands of sugar molecules â
Deoxyribose
â from each of which is suspended a parallel series of four types of molecule known as
Nucleic Acids
â Adenine, Guanine, Cytosine and Thymine (referred to by their initials AGCT) â arranged in sequence. The chemical bonds linking the two parallel chains of nucleic acids form the âsteps' of the staircase. The combination of the
D
eoxyribose and the
N
ucleic
A
cid steps gives us
DNA
.
The profound significance of this âstaircase structure' is that it is particularly well suited to the replication of genetic information every time the cell divides, as Watson and Crick described:
We imagine that, prior to duplication, the bonds [connecting the two parallel chains of nucleic acids or ânucleotides'] are broken and the two chains unwind and separate [the staircase, as it were, splits down the middle]. Each chain then acts as a template for the formation on to itself of a new companion chain, so that eventually we shall have two pairs of chains where we only had one before. Moreover the sequence of the pairs of nucleotides will have been duplicated exactly.
3
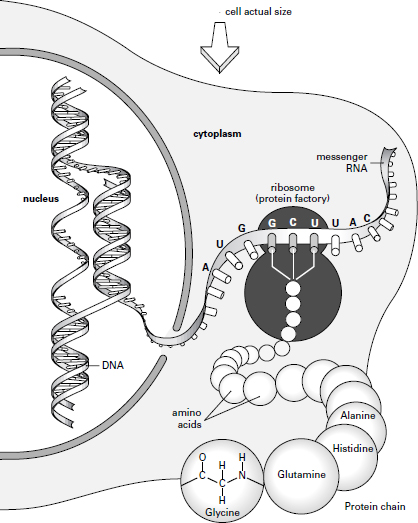
The double helix of DNA consists of two parallel strands of deoxyribose sugar molecules, to which are attached a sequence of nucleotides â AGCT â arranged in threes. The genetic instruction for a protein is conveyed by a strand of messenger RNA (mRNA) that passes out of the nucleus into the cytoplasm, where it feeds its coded instructions into a ribosome or protein factory.
Next it is necessary to clarify the manner in which the nucleic acids (or nucleotides) form the âgenes' that code for the tens of thousands of different proteins (enzymes, hormones, etc.). Each protein is made up of a unique combination of twenty types of simple building-blocks known as amino acids. Alone, the four nucleotides (AGCT) could only code for four amino acids, but if they are arranged in threes (or triplets) â such as CCG or CGC or GCG or similar variants â there are actually sixty-four possible permutations, which is more than sufficient to code for one or other of the twenty amino acids. So a gene made up of ninety nucleotides arranged in threes will code for thirty amino acids that make up a single protein.
Finally, we need a mechanism by which the âmessage' of the gene (the sequence of ninety nucleotides) is turned into the thirty amino acids that make up the protein. The section of DNA that includes the gene unravels and acts as a template for the building of a parallel sequence of nucleotides, known as messenger RNA (or mRNA) because it carries the message of the gene. The mRNA passes through the wall of the nucleus out into the cytoplasm of the cell, where it is picked up by a protein-making factory, a ribosome. Like a ticker tape, the mRNA feeds itself into the ribosome, which reads off the first triplet of nucleotides and then pulls in from the immediate vicinity the relevant amino acid for that triplet. It reads off the next triplet and then pulls in another amino acid, and so on. So,
from a gene made up of a sequence of ninety nucleotides one gets a unique arrangement of thirty amino acids that makes up one protein molecule.
This then, in a grotesquely oversimplified outline, is what Francis Crick described in 1958 as the âcentral dogma' of genetics: âDNA makes RNA makes protein'.
4
The corollary is obvious. The fault, or mutation, in genetic diseases arises because of a faulty arrangement of the sequence of nucleotides of the gene. This results in a faulty message being transmitted by the mRNA, leading to a faulty arrangement of amino acids, causing the faulty protein, which in the case of the genetic disease cystic fibrosis results in damage to the lung, and in Huntington's chorea results in degeneration of the nerve cells in the brain.
5
It is impossible to convey the scale of the intellectual problems that had to be surmounted before this mechanism of gene action became clear, nor indeed to describe the sheer sense of excitement experienced by the scientists over the fifteen years that it took to work it all out. Nonetheless it is important to appreciate that as of 1970 this understanding of the workings of DNA had no practical application at all, nor indeed did there seem to be the slightest prospect that it might. The molecular biologists had established this mechanism by which the gene acted â âDNA makes RNA makes protein' â from experiments on the bacterium
E. coli
, but the âdetails' of the individual genes remained completely inaccessible, concealed somewhere in the virtually infinite amount of information encoded within DNA, compressed into the virtually infinitely small space of the nucleus. Christopher Wills, Professor of Biology at the University of California, draws an appropriate analogy:
I have just with some difficulty hefted
Webster's Third New International Dictionary
onto my lap. This is the one that you
see in libraries, sitting proudly on its own little lectern. I find there are about sixty letters to a line, 150 lines to a column and three columns to a page. This works out at 27,000 different letters to a page. The dictionary has roughly 2,600 pages adding up to 70 million letters in all. Since there are about 3 billion nucleotide molecules in the human genome, it would take 43 volumes the size of this enormous dictionary simply to list the information that they carry. Let us call each of these volumes a Webster. Each Webster is three and a half inches thick so a human genome's worth of information in the form of 43 Websters would fill a shelf 12 feet long . . . Suppose you took one of these Websters off the shelf and opened it at random, you would be confronted with a grey expanse of featureless type, with no spaces and no breaks into paragraphs. Examined more closely each line would look something like this:
TTTTTTTTTGAGAGATTTGCTGCTGCT
There would be, in each volume of this library of 43 books, over a million such lines of type all looking at first glance the same.
In reality, of course, each nucleotide molecule is minuscule compared to the capital letter (CGAT) used to represent it, so stringing together the 3 billion nucleotides of DNA results in a continuous strand only 25mm long. But these 25mm have to be packed into the nucleus of a cell about 0.005mm across, and in achieving this extraordinary feat
the DNA molecules pack over a hundred trillion times as much information by volume as the most sophisticated
computerised information system that human intelligence has been able to devise.
6
It is appropriate to stop here for a moment's reflection. The single-celled conceptus, immediately after fertilisation, contains within its nucleus this trillion-times-miniaturised forty-three Webster volumes' worth of genetic information, which over the next few months will replicate itself billions of times. Somehow the genes âknow' how to instruct the individual cells, first, to form the basic structure of the foetus with a back and front, head and limbs, and then to instruct the cells to fulfil the specialised functions of a nerve or a muscle or a liver cell, and then to instruct the specialised cells to grow through childhood and adolescence to adulthood and, in this process, to link up and interact with each other to form the functioning organs of the brain, the heart and the liver. This extraordinary potential of the biological information locked within the nucleus of each cell can best be conceived of as the mirror image of the infinite size and grandeur of the Universe.
It is little wonder then that in 1970 most molecular biologists, having worked out in outline the mechanism of the action of the genes as reflected in âDNA makes RNA makes protein', believed they had reached the limits of what they could achieve. There was simply no way of locating within the vast impenetrable haystack of genetic information the individual straws of nucleotide sequences that made up the separate genes. âThe time of the great elucidation has come and gone,' wrote Nobel Prize winner Sir MacFarlane Burnet in 1969, as âthe great objective' of understanding how the genes work had been completed and âno one can discover that again'.
7
Or, in the words of another molecular biologist, âat the dawn of the 1970s [only] a handful of cranks in the world thought it was not yet time to
wind up fundamental research on DNA. Nobody listened to them or took them seriously.'
8
And yet, amazingly, âthe handful of cranks' were to be vindicated as over the next ten years four technical innovations cracked the apparently impenetrable complexity of the genes wide open.
Cutting the text
: The first task was to try to isolate the individual straws of nucleotide sequences within the haystack of the genome to permit them to be scrutinised in greater detail.
Viruses, as the smallest of all organisms, do not have sufficient space within their cells to make the proteins necessary for their own survival and replication, so they infect organisms larger than themselves such as bacteria (or humans), and âborrow' their protein-making machinery. Once inside the cell, they incorporate their own genes into those of the bacterium, so it starts producing the proteins necessary for their (the viruses') survival. Anthropomorphically speaking, the bacteria resent being hijacked in this way and in retaliation produce a series of enzymes that immobilise the virus by chopping its genes up into little useless fragments. The first of these ârestriction enzymes', as they are called â or, in popular terminology, âDNA text-cutters' â was discovered in 1968. A further 150 were identified over the following decade. Thus the addition of a combination of these text-cutters to human DNA cuts the three-billion-long string of nucleotides up into a series of more manageable sequences or, to put it another way, they make it possible to tear pages out of the forty-three volumes of Webster's dictionary.
9
Photocopying
: But these single fragments (or pages) by themselves are still just an incomprehensible string of nucleotides â CGAT etc. etc. etc.
ad
, virtually,
infinitum
â so some means had to be found of, as it were, photocopying them hundreds of times, so
that many different scientists can endeavour to work out what they mean. This brings us to the second technique, which exploits another important aspect of bacterial life.
Bacteria are asexual creatures and reproduce themselves by the simple expedient of dividing in two. They can, however, still swap genetic information between each other, thanks to a small circular string of DNA (or plasmid), quite distinct from the DNA of its own genes, which can be transferred like pass-the-parcel from one bacterium to another. In this way bacteria can âpass around' the genes for resistance to antibiotics, which explains why they can all suddenly become resistant to, say, penicillin. If it were possible to get hold of a plasmid, make an incision in the circle of DNA so that it opens out into a string, insert a fragment of human DNA (obtained by the use of text-cutter enzymes), âreseal' the plasmid and reinsert it back into the bacterium, then, every time it divides, so would the plasmid. After several divisions it would end up with large numbers of photocopied versions of the human DNA fragment. This was first achieved in 1973 and a couple of years later an industrious Harvard scientist, Thomas Maniatis, had completed a âlibrary' of DNA sequences covering the whole of the human genome.
10