XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (108 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

The xs:NOTATION Type
The
xs:NOTATION
type is perhaps the weirdest primitive type in the whole armory. It's provided to give backward compatibility with a rarely used feature in DTDs.
In a DTD you can define an unparsed entity like this:
PUBLIC “-//MEGACORP//WEATHER/” NDATA JPEG>
This example refers to a binary file
weather.jpeg
, and the
NDATA
part tells you that its format is
JPEG
. The keyword
NDATA
can be read as “Non-XML Data”.
This declaration is only valid if
JPEG
is the name of a notation defined somewhere in the DTD, for example:
The theory is that the system identifier tells the application what the name
JPEG
actually means. Unfortunately, there is no standardization of the URIs you can use here, so this doesn't work all that well in practice. I've used the registered media type (or MIME type) for
JPEG
as if it were a URI, but this isn't universal practice.
Elsewhere in the DTD you can define an attribute whose value is required to be one of a number of specified notations, for example:
format NOTATION (JPEG|GIF) “JPEG”
src ENTITY #REQUIRED
>
This defines an element,
, whose content is empty, and which has two attributes: a
format
attribute of type
NOTATION
, whose value must be
JPEG
or
GIF
, with the default being
JPEG
, and a
src
attribute, whose value must be the name of an unparsed entity defined in the DTD.
You can't actually declare unparsed entities in a schema (for that, you need to continue using a DTD), but you can declare attributes whose values must be entity names or notation names. The schema equivalent to the DTD declarations above would be:
Note that you can't declare an attribute whose type is
xs:NOTATION
, it must be a subtype of
xs:NOTATION
that is restricted to a specific list of allowed values. This all mirrors the rules for use in DTDs, and is all designed to ensure that users whose document types make use of unparsed entities and notations aren't prevented from taking advantage of XML Schema.
Although notations were added to XML Schema for backward compatibility reasons, the schema working group added an extra feature: they made notation names namespace-aware. In the schema above, the notation name JPEG
JPEG is interpreted as a local name defined within the target namespace of the containing schema. If the target namespace is anything other than the null namespace, then the notation name actually used in the source document (and in the
is interpreted as a local name defined within the target namespace of the containing schema. If the target namespace is anything other than the null namespace, then the notation name actually used in the source document (and in the
So, how is
xs:NOTATION
supported in XPath 2.0? The answer is, minimally. There are two things that are allowed:
- You can compare two
xs:NOTATION
values to see if they are equal, or not equal. - You can cast an
xs:NOTATION
value to a string.
Casting a string to a subtype of
xs:NOTATION
(but not to
xs:NOTATION
itself) is allowed provided that the string is supplied as a literal, so that the operation can be done at compile time. There is no way of constructing an
xs:NOTATION
value dynamically within an XPath expression; the only way you can get one is by reading the content of an attribute whose type annotation is
xs:NOTATION
.
This completes our survey of the “minor” types: that is, the types that are defined in XML Schema as primitive types, but which have fairly specialized applications (to put it politely). The next two sections deal with the two families of derived types that are predefined in XML Schema: the derived numeric types, and the derived string types.
Derived Numeric Types
XML Schema defines a range of types defined by restriction from
xs:integer
. They differ in the range of values permitted. The following table summarizes these types, giving the permitted value range for each one.
| Type | Minimum | Maximum |
| xs:byte | -128 | 127 |
| xs:int | -2147483648 | 2147483647 |
| xs:long | -2 63 | 2 63 -1 |
| xs:negativeInteger | no minimum | -1 |
| xs:nonNegativeInteger | 0 | no maximum |
| xs:nonPositiveInteger | no minimum | 0 |
| xs:positiveInteger | 1 | no maximum |
| xs:short | -32768 | 32767 |
| xs:unsignedByte | 0 | 255 |
| xs:unsignedInt | 0 | 4294967295 |
| xs:unsignedLong | 0 | 2 64 -1 |
| xs:unsignedShort | 0 | 65535 |
The type hierarchy for these types is shown in
Figure 5-2
.
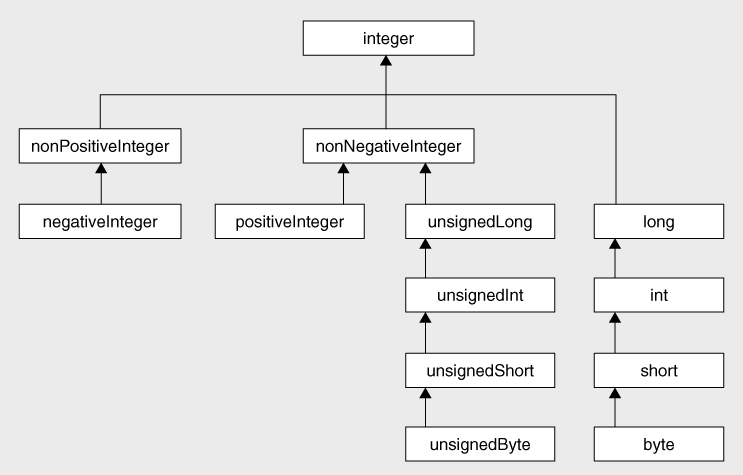
The range of values permitted in an
xs:integer
is unspecified. The specification says that at least 18 digits must be supported, but since the maximum value of an
xs:unsignedLong
is 18,446,744,073,709,551,615, it is clear that 18 digits is not actually sufficient. Some implementations (Saxon for example) allow arbitrary length integers.
I'm not a great enthusiast for these types. Their ranges are matched to the capacity of bits and bytes in the hardware, rather than to value ranges that actually occur in the real world. If you want to hold a percentage, and its value is an integer in the range 0 to 100, I would recommend defining a type with that specific range, rather than using an off-the-shelf type such as
unsignedByte
. This then leaves the question of which type to derive it from. There are 10 types in the above list that you could choose from. My own choice would be to derive it directly from
xs:integer
, on the grounds that any other choice is arbitrary. However, if you are using a data binding tool that generates Java or C# types equivalent to your schema types, then
xs:int
may work better.
As far as schema validation is concerned, it really doesn't matter very much what the type hierarchy is: if you define your percentage type with a
minInclusive
value of 0 and a
maxInclusive
value of 100, then the validator will do its work without needing to know what type it is derived from. When it comes to XPath processing, however, the type hierarchy starts to become more significant. For example, if a function is defined that accepts arguments of type
xs:positiveInteger
, then a value of type
my:percentage
will be accepted if
my:percentage
is derived by restriction from
xs:positiveInteger
, but not if
my:percentage
is derived from
xs:int
. The fact that every valid percentage is also a valid
xs:int
doesn't come into it; the value is substitutable only if the type is defined as a subtype of the required type in the type hierarchy.
In the standard function library, there are a number of functions that return integers, for example
count()
,
position()
, and
month-from-Date()
. There are also a few functions that require an integer as one of the arguments, for example,
insert-before()
,
remove()
, and
round-half-to-even()
. All these functions are described in Chapter 13. In all cases the type that appears in the function signature is
xs:integer
, rather than one of its subtypes. In many cases a subtype could have been used; for example,
count()
could have been defined to return an
xs:nonNegativeInteger
, while
position()
could have been defined to return
xs:positiveInteger
. But this wasn't done, and it's interesting to see why.
Firstly, consider functions that accept an integer as an argument, such as
remove()
. Here the integer represents the position of the item to be removed. This could have been defined as an
xs:positiveInteger
, because the only values that make sense are greater than zero (positions in a sequence are always numbered from one). But if this were done then the function callremove($seq, 1)would give a type error, on the curious grounds that 1 is not an
xs:positiveInteger
. This is because, when you supply a value in a context where a particular type is required, the type checking rules rely on the label attached to the value, they don't consider the value itself. The type label attached to the integer literal1is
xs:integer
, and
xs:integer
is not a subtype of
xs:positiveInteger
, so the call fails.