XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (23 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

The base URI is maintained explicitly only for document nodes, element nodes, and processing instruction nodes. For attributes, text nodes, and comments, and for elements and processing instructions without an explicit base URI of their own, the base URI is the same as the URI of its parent node.
For a namespace node the base URI is ()
() , the empty sequence. The system doesn't attempt to go to the parent node to find its base URI. This is rather a curiosity. The only time you might be interested in the base URI of a namespace node is if you are using the namespace URI as the URI of a real resource, for example a schema. But even then, the base URI will only be needed if this is a relative URI reference. W3C, after fierce debate, decided that a relative namespace URI was deprecated and implementation defined, so the working groups steered clear of defining an interpretation for it.
, the empty sequence. The system doesn't attempt to go to the parent node to find its base URI. This is rather a curiosity. The only time you might be interested in the base URI of a namespace node is if you are using the namespace URI as the URI of a real resource, for example a schema. But even then, the base URI will only be needed if this is a relative URI reference. W3C, after fierce debate, decided that a relative namespace URI was deprecated and implementation defined, so the working groups steered clear of defining an interpretation for it.
The fact that text nodes don't have their own base URI is a little ad hoc, because a text node need not come from the same external entity as its parent element, but it reflects the decision that text nodes should be joined up irrespective of entity boundaries.
The base URI of a node in a source document is used almost exclusively for one purpose: to resolve relative URI references when loading additional input documents using the
doc()
or
document()
functions, described in Chapter 13. The base URI is accessible using the
base-uri()
function, which is also described in Chapter 13.
The Children of a Node
A node has a sequence of child nodes. This one-to-many relationship is defined for all nodes, but the list will be empty for all nodes other than document nodes and element nodes. So you can ask for the children of an attribute, and you will get an empty sequence returned.
The children of an element are the elements, text nodes, processing instructions, and comments contained textually between its start and end tags, provided that they are not also children of some lower-level element.
The children of the document node are all the elements, text nodes, comments, and processing instructions that aren't contained in another element. For a well-formed document the children of the root node will be the outermost element plus any comments or processing instructions that come before or after the outermost element.
The attributes of an element are not regarded as children of the element; neither are its namespace nodes.
The Parent of a Node
Every node, except a node at the root of a tree, has a parent. A document node never has a parent. Other kinds of node usually have a parent, but they may also be parentless. The parent relationship is
not
the exact inverse of the child relationship: specifically, attribute nodes and namespace nodes have an element node as their parent,
but they are not considered to be children of that element
. In other cases, however, the relationship is symmetric: elements, text nodes, processing instructions, and comments are always children of their parent node, which will always be either an element or the document node.
Two nodes that are both children of the same parent are referred to as being
siblings
of each other. (In case you are not a native English speaker, the word “sibling” means “brother or sister.”)
The Attributes of a Node
This relationship only exists in a real sense between element nodes and attribute nodes, and this is how it is shown on the diagram at the end of this section. It is a one-to-many relationship: one element has zero or more attributes. The relationship
hasAttributes
is defined for all nodes, but if you ask for the attributes of any node other than an element, the result will be an empty sequence.
The Namespaces of a Node
This relationship only really exists between element nodes and namespace nodes, and this is how it is shown on the diagram. It is a one-to-many relationship: one element has zero or more namespace nodes. Like the
hasAttributes
relationship, the relationship
hasNamespaces
is defined for all nodes, so if you ask for the namespaces of any node other than an element, the result will be an empty sequence.
Note that each namespace node is owned uniquely by one element. If a namespace declaration in the source document has a scope that includes many elements, then a corresponding namespace node will be generated for each one of these elements. These nodes will all have the same name and string value, but they will be distinct nodes for the purposes of counting and using theisoperator (which tests whether its two operands are references to the same node: see Chapter 8).
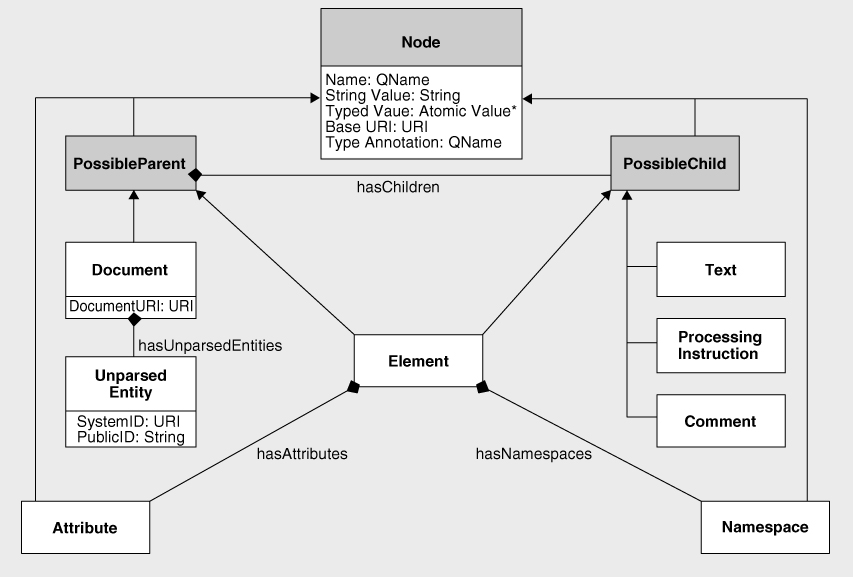
Completing the UML Class Diagram
It's now possible to draw a more complete UML class diagram, as shown in
Figure 2-7
. In this version:
- I brought out
PossibleParent
and
PossibleChild
as separate (abstract) classes, to group those nodes that can be parents (document and element nodes) and those nodes that can be children (elements, text nodes, comments, and processing instructions). Abstract classes are shown as shaded boxes on the diagram. Note that elements fall into both categories. This grouping is for illustration only, and in reality the relationships
hasChildren
,
hasAttributes
, and
hasNamespaces
are available for all kinds of node, they just return an empty sequence when the node is not a document or element node. - I identified the
hasChildren
relationship between an element or document node and its children. - I identified the separate relationships between an element and its attributes, and between an element and its namespace nodes.
- I identified the additional class
UnparsedEntity
. This is not itself a node on the tree. It corresponds to an unparsed entity declaration within the document's DTD. Unparsed entities are exposed by the functions
unparsed-entity-uri()
and
unparsed-entity-public-id()
available in XSLT (see Chapter 13), but they are second-class citizens, because there is no way to create an unparsed entity in an output document.
It's worth mentioning that XDM never uses null values in the sense that SQL or Java use null values. If a node has no string value, then the value returned is the zero-length string. If a node has no children, then the value returned is the empty sequence, a sequence containing no items.
Let's look briefly at some of the other features of this model.
Document Order
Nodes within a tree have an ordering, called
document order
. Where two nodes come from the same tree, their relative position in document order is based on their position in the tree, which in turn is based on the ordering of the underlying constructs in the original textual XML document. For example, an element precedes its children in document order, and sibling nodes are listed in the same order as they appear in the original source document. By convention an element node is followed by its namespace nodes, then its attributes, and then its children, but the ordering of the namespace nodes among themselves, and of the attribute nodes among themselves, is unpredictable.
Where two nodes come from different trees, they still have a document order, but it is not predictable what it will be. In fact, any sequence of nodes can be sorted into document order, whether the nodes come from the same document or different documents, and if you sort the same sequence into document order more than once, you will always get the same result, but in the case of nodes from different documents, you can't predict which one will come first. The spec does say, however, that nodes from different documents will not be interleaved: a node from document A will never come after one node from document B and before another node from document B.
There are a number of XPath expressions that always return nodes in document order. These include all path expressions (any expression using the/operator), step expressions such asancestor::*, and expressions using the operators
union
(or|),
intersect
, and
except
. If you want to sort a sequence
$seq
into document order, you can do this with the trivial path expression$seq/., or by forming a union with the empty sequence:$seq|().