Bad Science (5 page)
Authors: Ben Goldacre
Tags: #General, #Life Sciences, #Health & Fitness, #Errors, #Health Care Issues, #Essays, #Scientific, #Science

There is a long history of upset being caused by trials, in medicine as much as anywhere, and all kinds of people will mount all kinds of defenses against them. Archie Cochrane, one of the grandfathers of evidence-based medicine, once amusingly described how different groups of surgeons were each earnestly contending that their treatment for cancer was the most effective; it was transparently obvious to them all that their own treatment was the best. Cochrane went so far as to bring a collection of them together in a room, so that they could witness one another’s dogged but conflicting certainty, in his efforts to persuade them of the need for trials. Judges, similarly, can be highly resistant to the notion of trialing different forms of sentence for heroin users, even though there is no evidence to say which kind of sentence (custodial, compulsory drug treatment, and so on) is best. They believe that they can divine the most appropriate sentence in each individual case, without the need for experimental data. These are recent battles, and they are in no sense unique to the world of homeopathy.
So, we take our group of people coming out of a homeopathy clinic, we switch half their pills for placebo pills, and we measure who gets better. That’s a placebo-controlled trial of homeopathy pills, and this is not a hypothetical discussion; these trials have been done on homeopathy, and it seems that overall, homeopathy does no better than placebo.
And yet you will have heard homeopaths say that there are positive trials in homeopathy; you may even have seen specific ones quoted. What’s going on here? The answer is fascinating, and takes us right to the heart of evidence-based medicine. There are
some
trials that find homeopathy performs better than placebo, but only some, and they are, in general, trials with “methodological flaws.” This sounds technical, but all it means is that there are problems in the way the trials were performed, and those problems are so great that they mean the trials are less “fair tests” of a treatment.
The alternative therapy literature is certainly riddled with incompetence, but flaws in trials are actually very common throughout medicine. In fact, it would be fair to say that all research has some flaws, simply because every trial will involve a compromise between what would be ideal and what is practical or cheap. (The literature from complementary and alternative medicine—CAM—often fails badly at the stage of interpretation; medics sometimes know if they’re quoting duff papers and describe the flaws, whereas homeopaths tend to be uncritical of anything positive.)
That is why it’s important that research is always published, in full, with its methods and results available for scrutiny. This is a recurring theme in this book, and it’s important, because when people make claims based upon their research, we need to be able to decide for ourselves how big the “methodological flaws” were, and come to our own judgment about whether the results are reliable, whether theirs was a “fair test.” The things that stop a trial from being fair are, once you know about them, blindingly obvious.
Blinding
One important feature of a good trial is that neither the experimenters nor the patients know if they got the homeopathy sugar pill or the simple placebo sugar pill, because we want to be sure that any difference we measure is the result of the difference between the pills and not of people’s expectations or biases. If the researchers knew which of their beloved patients were having the real and which the placebo pills, they might give the game away or it might change their assessment of the patient—consciously or unconsciously.
Let’s say I’m doing a study on a medical pill designed to reduce high blood pressure. I know which of my patients are having the expensive new blood pressure pill and which are having the placebo. One of the people on the swanky new blood pressure pills comes in and has a blood pressure reading that is way off the scale, much higher than I would have expected, especially since he’s on this expensive new drug. So I recheck his blood pressure, “just to make sure I didn’t make a mistake.” The next result is more normal, so I write that one down and ignore the high one.
Blood pressure readings are an inexact technique, like ECG interpretation, X-ray interpretation, pain scores, and many other measurements that are routinely used in clinical trials. I go for lunch, entirely unaware that I am calmly and quietly polluting the data, destroying the study, producing inaccurate evidence, and therefore, ultimately, killing people (because our greatest mistake would be to forget that data is used for serious decisions in the very real world, and bad information causes suffering and death).
There are several good examples from recent medical history where a failure to ensure adequate blinding, as it is called, has resulted in the entire medical profession’s being mistaken about which was the better treatment. We had no way of knowing whether keyhole surgery was better than open surgery, for example, until a group of surgeons from Sheffield came along and did a very theatrical trial, in which bandages and decorative fake blood squirts were used, to make sure that nobody could tell which type of operation anyone had received.
Some of the biggest figures in evidence-based medicine got together and did a review of blinding in all kinds of trials of medical drugs and found that trials with inadequate blinding exaggerated the benefits of the treatments being studied by 17 percent. Blinding is not some obscure piece of nitpicking, idiosyncratic to pedants like me, used to attack alternative therapies.
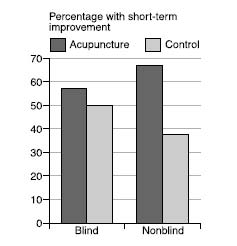
Closer to home for homeopathy, a review of trials of acupuncture for back pain showed that the studies that were properly blinded showed a tiny benefit for acupuncture, which was not “statistically significant” (we’ll come back to what that means later). Meanwhile, the trials that were not blinded—the ones in which the patients knew whether they were in the treatment group or not—showed a massive, statistically significant benefit for acupuncture. (The placebo control for acupuncture, in case you’re wondering, is sham acupuncture, with fake needles or needles in the “wrong” places, although an amusing complication is that sometimes one school of acupuncturists will claim that another school’s sham needle locations are actually their genuine ones.)
So, as we can see, blinding is important, and not every trial is necessarily any good. You can’t just say, “Here’s a trial that shows this treatment works,” because there are good trials, or “fair tests,” and there are bad trials. When doctors and scientists say that a study was methodologically flawed and unreliable, it’s not because they’re being mean, or trying to maintain the “hegemony,” or to keep the backhanders coming from the pharmaceutical industry; it’s because the study was poorly performed—it costs nothing to blind properly—and simply wasn’t a fair test.
Randomization
Let’s take this out of the theoretical, and look at some of the trials that homeopaths quote to support their practice. I’ve got in front of me, a standard review of trials for homeopathic arnica by homeopathist professor Edzard Ernst,
7
which we can go through for examples. We should be absolutely clear that the inadequacies here are not unique, I do not imply intent to deceive, and I am not being mean. What we are doing is simply what medics and academics do when they appraise evidence.
So, Hildebrandt et al. (as they say in academia) looked at forty-two women taking homeopathic arnica for delayed-onset muscle soreness and found it performed better than placebo. At first glance this seems to be a pretty plausible study, but if you look closer, you can see there was no randomization described. Randomization is another basic concept in clinical trials. We randomly assign patients to the placebo sugar pill group or the homeopathy sugar pill group, because otherwise there is a risk that the doctor or homeopath—consciously or unconsciously—will put patients who they think might do well into the homeopathy group and the no-hopers into the placebo group, thus rigging the results.
Randomization is not a new idea. It was first proposed in the seventeenth century by Jan Baptista van Helmont, a Belgian radical who challenged the academics of his day to test their treatments like bloodletting and purging (based on “theory”) against his own, which he said were based more on clinical experience: “Let us take out of the hospitals, out of the Camps, or from elsewhere, two hundred, or five hundred poor People, that have Fevers, Pleurisies, etc. Let us divide them into half, let us cast lots, that one half of them may fall to my share, and the other to yours…We shall see how many funerals both of us shall have.”
It’s rare to find an experimenter so careless that he’s not randomized the patients at all, even in the world of CAM. But it’s surprisingly common to find trials in which the method of randomization is inadequate: they look plausible at first glance, but on closer examination we can see that the experimenters have simply gone through a kind of theater, as if they were randomizing the patients but still leaving room for them to influence, consciously or unconsciously, which group each patient goes into.
In some inept trials, in all areas of medicine, patients are randomized into the treatment or placebo group by the order in which they are recruited into the study: the first patient in gets the real treatment, the second gets the placebo, the third the real treatment, the fourth the placebo, and so on. This sounds fair enough, but in fact, it’s a glaring hole that opens your trial up to possible systematic bias.
Let’s imagine there is a patient who the homeopath believes to be a no-hoper, a “heart-sink” patient who’ll never really get better, no matter what treatment he or she gets, and the next place available on the study is for someone going into the “homeopathy” arm of the trial. It’s not inconceivable that the homeopath might just decide—again, consciously or unconsciously—that this particular patient “probably wouldn’t really be interested” in the trial. But if, on the other hand, this no-hoper patient had come into clinic at a time when the next place on the trial was for the placebo group, the recruiting clinician might have felt a lot more optimistic about signing him up.
The same goes for all the other inadequate methods of randomization: by last digit of date of birth, by date seen in clinic, and so on. There are even studies that claim to randomize patients by tossing a coin, but forgive me (and the entire evidence-based medicine community) for worrying that tossing a coin leaves itself just a little bit too open to manipulation. Best of three, and all that. Sorry, I meant best of five. Oh, I didn’t really see that one: it fell on the floor.
There are plenty of genuinely fair methods of randomization, and although they require a bit of effort, they come at no extra financial cost. The classic is to make people call a special telephone number, to where someone is sitting with a computerized randomization program (and the experimenter doesn’t even do that until the patient is fully signed up and committed to the study). This is probably the most popular method among meticulous researchers, who are keen to ensure they are doing a “fair test,” simply because you’d have to be an out-and-out charlatan to mess it up, and you’d have to work pretty hard at the charlatanry too.
Does randomization matter? As with blinding, people have studied the effect of randomization in huge reviews of large numbers of trials and found that the ones with dodgy methods of randomization overestimate treatment effects by 41 percent. In reality, the biggest problem with poor-quality trials is not that they’ve used an inadequate method of randomization; it’s that they don’t tell you
how
they randomized the patients at all. This is a classic warning sign and often means the trial has been performed badly. Again, I do not speak from prejudice: trials with unclear methods of randomization overstate treatment effects by 30 percent, almost as much as the trials with openly rubbish methods of randomization.
In fact, as a general rule it’s always worth worrying when people don’t give you sufficient details about their methods and results. As it happens (I promise I’ll stop this soon), there have been two landmark studies on whether inadequate information in academic articles is associated with dodgy, overly flattering results, and yes, studies that don’t report their methods fully do overstate the benefits of the treatments, by around 25 percent. Transparency and detail are everything in science. Hildebrandt et al., through no fault of their own, happened to be the peg for this discussion on randomization (and I am grateful to them for it). They might well have randomized their patients. They might well have done so adequately. But they did not report on it.
Let’s go back to the eight studies in Ernst’s review article on homeopathic arnica, which we chose pretty arbitrarily, because they demonstrate a phenomenon that we see over and over again with complementary and alternative medicine (CAM) studies: most of the trials were hopelessly methodologically flawed and showed positive results for homeopathy, whereas the couple of decent studies—the most “fair tests”—showed homeopathy to perform no better than placebo.
8