XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (38 page)
Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay

In this example, the value of the variable is a document node, which contains the
One popular way to use a temporary document is as a lookup table. The following stylesheet fragment uses data held in a temporary document to get the name of the month, given its number held in a variable
$mm
.
…
Of course, the sequence constructor does not have to contain constant values as in these two examples; it can also contain instructions such as
This creates the tree illustrated in
Figure 2-10
. Each box shows a node; the three layers are respectively the node kind, the node name, and the string value of the node. Once again, an asterisk indicates that the string value is the concatenation of the string values of the child nodes.
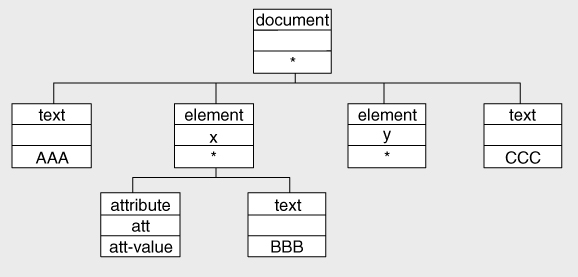
In XSLT 1.0, temporary documents went under the name of
result tree fragments
. I introduced the term
temporary tree
in an earlier edition of this book, because I felt that the phrase
result tree fragment
undervalued the range of purposes to which these structures can be applied. In fact, result tree fragments in XSLT 1.0 were very limited in their capability because of a quite artificial restriction that prevented them being accessed using path expressions. Most vendors ended up circumventing this restriction using an extension function generally named
xx:node-set()
, where
xx
refers to the vendor's particular namespace. In XSLT 2.0, the restriction is gone for good, and temporary documents can now be used in exactly the same way as any source document: they can be used as the result tree for one phase of transformation, and the source tree for the next.
The restrictions in XSLT 1.0 were defined by making result tree fragments a separate data type, with a restricted range of operations available. In XSLT 2.0, a temporary document is a tree rooted at a document node just like any other, and is manipulated using variables or expressions that refer to its root node. (In XSLT 2.0 you can also have trees rooted at elements, or even at attributes or text nodes—though in that case there will only be one node in the tree. In fact, you might sometimes prefer to use a sequence of parentless elements rather than a document. But because of the XSLT 1.0 legacy, a temporary document is what you get when you declare an as
as attribute.)
attribute.)
A temporary document does not necessarily correspond to a well-formed XML document, for example the document node can own text nodes directly, and it can have more than one element node among its children. However, it must conform to the same rules as an XML external parsed entity; for example, all the attributes belonging to an element node must have distinct names.
The ability to use temporary documents as intermediate results in a multiphase transformation greatly increases the options available to the stylesheet designer (which is why the
xx:node-set()
extension function was so popular in XSLT 1.0). The general structure of such a stylesheet follows the pattern:
Some people prefer to use local variables for the intermediate results, some use global variables; it makes little difference.
One way that I often use multiphase transformations is to write a preprocessor for some specialized data source, to convert it into the format expected by an existing stylesheet module that renders it into HTML. For example, to create a glossary as an appendix in a document, you may want to write some code that searches the document for terms and their definitions. Rather than generating HTML directly from this code, you can generate the XML vocabulary used in the rest of the document, and then reuse the existing stylesheet code to render this as phase two of your transformation. This coding style is sometimes referred to as a micro-pipeline.
Because multiphase transformations are often used to keep stylesheets modular, some discipline is required to keep the template rules for each phase separate. I generally do this in two ways:
- Keep the rules for each phase of transformation in a separate stylesheet module. Stylesheet modules are discussed in Chapter 3.
- Use a different mode for each phase of the transformation. Modes were described earlier in this chapter, on page 78.
Summary
In this chapter we explored the important concepts needed to understand what an XSLT processor does, including the following:
- The overall system architecture, in which a stylesheet controls the transformation of a source tree into a result tree.
- The tree model used in XSLT, the way it relates to the XML standards, and some of the ways it differs from the DOM model.
- How template rules are used to define the action to be taken by the XSLT processor when it encounters particular kinds of node in the tree.
- The way in which expressions, data types, and variables are used in the XSLT language to calculate values.
The next chapter looks at the structure of an XSLT stylesheet in more detail.
Chapter 3
Stylesheet Structure
This chapter describes the overall structure of a stylesheet. In the previous chapter we looked at the processing model for XSLT and the data model for its source and result trees. In this chapter we will look in more detail at the different kinds of construct found in a stylesheet such as declarations and instructions, literal result elements, and attribute value templates.
Some of the concepts explained in this chapter are tricky; they are areas that often cause confusion, which is why I have tried to explain them in some detail. However, it's not necessary to master everything in this chapter before you can write your first stylesheet—so use it as a reference, coming back to topics as and when you need to understand them more deeply.
The topics covered in this chapter are as follows:
- Stylesheet modules
. We will discuss how a stylesheet program can be made up of one or more stylesheet modules, linked together with - The
- The
processing instruction. This links a source document to its associated stylesheet, and allows stylesheets to be embedded directly in the source document whose style they define. - A brief description of the
declarations
found in the stylesheet, that is, the immediate children of the - A brief description of each
instruction
that can be used in a stylesheet. In the previous chapter, I introduced the idea of a
sequence constructor
as a sequence of instructions that can be evaluated to produce a sequence of items, which will usually be nodes to be written to the result tree. This section provides a list of the instructions that can be used, with a quick summary of the function of each one. Full specifications of each instruction can be found in Chapter 6. - Simplified stylesheets
, in which the
elements are omitted, to make an XSLT stylesheet look more like the simple template languages that some users may be familiar with. - Attribute value templates
. These define variable attributes not only of literal result elements but of certain XSLT elements as well. - Facilities allowing the specification to be extended, both by vendors and by W3 C itself, without adversely affecting the portability of stylesheets.
- Handling of
whitespace
in the source document, in the stylesheet itself, and in the result tree.
Changes in XSLT 2.0
The important concepts in this chapter are largely unchanged from XSLT 1.0. The most significant changes are as follows:
- There are some terminology changes. Top-level elements are now called declarations. Templates (or
template bodies
as I called them in previous editions of this book) are now called sequence constructors—most people used the word template incorrectly to refer to an
stylesheet module
). - Some new declarations and instructions have been introduced.
- The concept of backward-compatibility mode has been introduced. This is invoked when a stylesheet specifiesversion = “1.0”and causes certain constructs to be handled in a way that is compatible with XSLT 1.0.
- The
use-when
attribute is introduced to allow parts of a stylesheet to be conditionally included or excluded at compile time. - In other areas, there has been a general tightening up of the rules. For example, the effect of specifyingxml:space = “preserve”in a stylesheet is now described much more precisely.
The Modular Structure of a Stylesheet
In the previous chapter, I described the XSLT processing model, in which a stylesheet defines the rules by which a source tree is transformed into a result tree.
Stylesheets, like programs in other languages, can become quite long and complex, and so there is a need to allow them to be divided into separate modules. This allows modules to be reused, and to be combined in different ways for different purposes: for example, we might want to use two different stylesheets to display press releases on-screen and on paper, but there might be components that both of these stylesheets share in common. These shared components can go in a separate module that is used in both cases.
We touched on another way of using multiple stylesheet modules in the previous chapter, where each module corresponds to one phase of processing in a multiphase transformation.
One can regard the complete collection of modules as a
stylesheet program
and refer to its components as
stylesheet modules
.
One of the stylesheet modules is the
principal stylesheet module
. This is in effect the main program, the module that is identified to the stylesheet processor by the use of an
processing instruction in the source document, or whatever command-line parameters or application programming interface (API) the vendor chooses to provide. The principal stylesheet module may fetch other stylesheet modules, using
The following example illustrates a stylesheet written as three modules: a principal module to do the bulk of the work, with two supporting stylesheet modules, one to obtain the current date, and one to construct a copyright statement.
Example: Using
Source
The input document,
sample.xml
, looks like this:
recommendation published by the World Wide Web Consortium
Stylesheets
The stylesheet uses
There are three modules in this stylesheet program:
principal.xsl
,
date.xsl
, and
copyright.xsl
. The
date.xsl
module uses the XSLT 2.0 function
current-date()
; the other modules will work equally well with XSLT 1.0 or 2.0.
When you run the transformation, you only need to name the principal stylesheet module on the command line—the other modules will be fetched automatically. The way this stylesheet is written, all the modules must be in the same directory.
When an XSLT 2.0 processor sees a module that specifies version = “1.0”
version = “1.0” , it must either run that module in backward-compatibility mode, or it must reject the stylesheet. The latest versions of Saxon and AltovaXML both support backward-compatibility mode, so this is not a problem. Saxon displays a health warning, required by the W3 C specifications, which you can safely ignore in this instance.
, it must either run that module in backward-compatibility mode, or it must reject the stylesheet. The latest versions of Saxon and AltovaXML both support backward-compatibility mode, so this is not a problem. Saxon displays a health warning, required by the W3 C specifications, which you can safely ignore in this instance.
If you try to run the stylesheet in XMLSpy, it will fail, reporting an error in the
date.xsl
module. This is because XMLSpy usesversion = “1.0”as a signal to invoke its XSLT 1.0 processor, but the module
date.xsl
uses XSLT 2.0 features.
principal.xsl
The first module,
principal.xsl
, contains the main logic of the stylesheet.
xmlns:xsl=“http://www.w3.org/1999/XSL/Transform”
version=“1.0”
>
It starts with two
The template rule for
$date
. This variable isn't defined in this stylesheet module, but it is present in the module
date.xsl
, so it can be accessed from here.
The template rule for
copyright
. Again, there is no template of this name in this module, but there is one in the module
copyright.xsl
, so it can be called from here.
Finally, the template rule that matches all other elements (match = “*”) has the effect of copying the element unchanged from the source document to the output. The
date.xsl
The next module,
date.xsl
, declares a global variable containing today's date. This calls the
current-date()
function in the standard XPath 2.0 function library, and the XSLT 2.0
format-date()
function, both of which are described in Chapter 13.
xmlns:xsl=“http://www.w3.org/1999/XSL/Transform”
version=“2.0”
xmlns:xs=“http://www.w3.org/2001/XMLSchema”
>
select=“format-date(current-date(), ‘[MNn] [D1o], [Y]’)”/>
Although this is a rather minimal module, there's a good reason why you might want to separate this code into its own module: it's dependent on XSLT 2.0, and you might want to write an alternative version of the function that doesn't have this dependency. Note that we've setversion = “2.0”on theversion = “1.0”.