Gödel, Escher, Bach: An Eternal Golden Braid (95 page)
Read Gödel, Escher, Bach: An Eternal Golden Braid Online
Authors: Douglas R. Hofstadter
Tags: #Computers, #Art, #Classical, #Symmetry, #Bach; Johann Sebastian, #Individual Artists, #Science, #Science & Technology, #Philosophy, #General, #Metamathematics, #Intelligence (AI) & Semantics, #G'odel; Kurt, #Music, #Logic, #Biography & Autobiography, #Mathematics, #Genres & Styles, #Artificial Intelligence, #Escher; M. C

Once an enzyme and its substrate are bound together, there is some disequilibrium of electric charge, and consequently charge-in the form of electrons and protons-flows around the bound molecules and readjusts itself. By the time equilibrium has been reached, some rather profound chemical changes may have occurred to the substrate. Some examples are these: there may have been a "welding", in which some standard small molecule got tacked onto a nucleotide, amino acid, or other common cellular molecule; a DNA strand may have been "nicked" at a particular location; some piece of a molecule may have gotten lopped off; and so forth. In fact, bio-enzymes do operations on molecules which are quite similar to the typographical operations which Typo-enzymes perform. However, most enzymes perform essentially only a single task, rather than a sequence of tasks. There is one other striking difference between Typoenzymes and bio-enzymes, which is this: whereas Typo-enzymes operate only on strands, bio-enzymes can act on DNA, RNA, other proteins, ribosomes, cell membranes-in short, on anything and everything in the cell. In other words, enzymes are the universal mechanisms for getting things done in the cell. There are enzymes which stick things together and take them apart and modify them and activate them and deactivate them and copy them and repair them and destroy them .. .
Some of the most complex processes in the cell involve "cascades" in which a single molecule of some type triggers the production of a certain kind of enzyme; the manufacturing process begins and the enzymes which come off the "assembly line" open up a new chemical pathway which allows a second kind of enzyme to be produced. This kind of thing can go on for three or four levels, each newly produced type of enzyme triggering the production of another type. In the end a "shower" of copies of the final type of enzyme is produced, and all of the copies go off and do their specialized thing, which may be to chop up some "foreign"
DNA, or to help make some amino acid for which the cell is very "thirsty", or whatever.
Need for a Sufficiently Strong Support System
Let us describe nature's solution to the puzzle posed for Typogenetics: "What kind of strand of DNA can direct its own replication?" Certainly not every strand of DNA is inherently a self-rep. The key point is this: any strand which wishes to direct its own copying must contain directions for assembling precisely those enzymes which can carry out the task. Now it is futile to hope that a strand of DNA in isolation could be a self-rep; for in order for those potential proteins to be pulled out of the DNA, there must not only be ribosomes, but also RNA polymerase, which makes the mRNA that gets transported to the ribosomes. And so we have to begin by assuming a kind of "minimal support system" just sufficiently strong that it allows transcription and translation to be carried out. This minimal support system will thus consist in (1) some proteins, such as RNA polymerase, which allow mRNA to be made from DNA, and (2) some ribosomes.
How DNA Self-Replicates
It is not by any means coincidental that the phrases "sufficiently strong support system" and
"sufficiently powerful formal system" sound alike. One is the precondition for a self-rep to arise, the other for a self-ref to arise. In fact there is in essence only one phenomenon going on in two very different guises, and we shall explicitly map this out shortly. But before we do so, let us finish the description of how a strand of DNA can be a self-rep.
The DNA must contain the codes for a set of proteins which will copy it. Now there is a very efficient and elegant way to copy a double-stranded piece of DNA, whose two strands are complementary. This involves two steps:
(1) unravel the two strands from each other;
(2) mate" a new strand to each of the two new single strands.
This process will create two new double strands of DNA, each identical to the original one.
Now if our solution is to be based on this idea, it must involve a set of proteins, coded for in the DNA itself, which will carry out these two steps.
It is believed that in cells, these two steps are performed together in a coordinated way, and that they require three principal enzymes: DNA endonuclease, DNA polymerase, and DNA ligase. The first is an "unzipping enzyme": it peels the two original strands apart for a short distance, and then stops. Then the other two enzymes come into the picture. The DNA polymerase is basically a copy-and-move enzyme: it chugs down the short single strands of DNA, copying them complementarily in a fashion reminiscent of the Copy mode in Typogenetics. In order to copy, it draws on raw materials-specifically nucleotides-which are floating about in the cytoplasm. Because the action proceeds in fits and starts, with some unzipping and some copying each time, some short gaps are created, and the DNA ligase is what plugs them up. The process is repeated over and over again. This precision three-enzyme machine proceeds in careful fashion all the way down the length of the DNA molecule, until the whole thing has been peeled apart and simultaneously replicated, so that there are now two copies of it.
Comparison of DNA's Self-Rep Method with Quining
Note that in the enzymatic action on the DNA strands, the fact that information is stored in the DNA is just plain irrelevant; the enzymes are merely carrying out their symbol-shunting functions, just like rules of inference in the MMIU-system. It is of no interest to the three enzymes that at some point they are actually copying the very genes which coded for them.
The DNA, to them, is just a template without meaning or interest.
It is quite interesting to compare this with the Quine sentence's method of describing how to construct a copy of itself. There, too, one has a sort of "double strand"-two copies of the same information, where one copy acts as instructions, the other as template. In DNA, the process is vaguely parallel, since the three enzymes (DNA endonuclease, DNA polymerase, DNA ligase) are coded for in just one of the two strands, which therefore acts as program, while the other strand is merely a template. The parallel is not perfect, for when the copying is carried out, both strands are used as template, not just one. Nevertheless, the analogy is highly suggestive. There is a biochemical analogue to the use-mention dichotomy: when DNA is treated as a mere sequence of chemicals to be copied, it is like mention of typographical symbols; when DNA is dictating what operations shall he carried out, it is like use of typographical symbols.
Levels of Meaning of DNA
There are several levels of meaning which can be read from a strand of DNA, depending on how big the chunks are which you look at, and how powerful a decoder you use. On the lowest level, each DNA strand codes for an equivalent RNA strand-the process of decoding being transcription. If one chunks the DNA into triplets, then by using a "genetic decoder", one can read the DNA as a sequence of amino acids. This is translation (on top of transcription). On the next natural level of the hierarchy, DNA is readable as a code for a set of proteins. The physical pulling-out of proteins from genes is called gene expression.
Currently, this is the highest level at which we understand what DNA means.
However, there are certain to be higher levels of DNA meaning which are harder to discern. For instance, there is every reason to believe that the DNA of, say, a human being codes for such features as nose shape, music talent, quickness of reflexes, and so on. Could one, in principle, learn to read off such pieces of information directly from a strand of DNA, without going through the actual physical process of epigenesis-the physical pulling-out of phenotype from genotype Presumably, yes, since-in theory-one could have an incredibly powerful computer program simulating the entire process, including every cell, every protein, every tiny feature involved in the replication of DNA, of cells, to the bitter end. The output of such a pseudo-epigenesis program would be a high-level description of the phenotype.
There is another (extremely faint) possibility: that we could learn to read the phenotype off of the genotype without doing an isomorphic simulation of the physical process of epigenesis, but by finding some simpler sort of decoding mechanism. This could be called
"shortcut pseudoepigenesis". Whether shortcut or not, pseudo-epigenesis is, of course, totally beyond reach at the present time-with one notable exception: in the species Felis catus, deep probing has revealed that it is indeed possible to read the phenotype directly off of the genotype. The reader will perhaps better appreciate this remarkable fact after directly examining the following typical section of the DNA of Felis catus:
CATCATCATCATCATCATCATCATCATCAT ...
Below is shown a summary of the levels of DNA-readability, together with the names of the different levels of decoding. DNA can be read as a sequence of:
bases (nucleotides)
transcription
amino acids
translation
proteins (primary structure)
. gene expression
proteins (tertiary structure)
protein clusters
higher levels of gene expression
…
….
unknown levels of DNA meaning
….
(N-1) ????
(N) physical, mental, and
psychological traits
pseudo-epigenesis
The Central Dogmap
.
With this background, now we are in a position to draw an elaborate comparison between F.
Crick's "Central Dogma of Molecular Biology" (.DOGMA I) upon which all cellular processes are based; and what I, with poetic license, call the "Central Dogma of Mathematical Logic" (.DOGMA II), upon which G6del's Theorem is based. The mapping from one onto the other is laid out in Figure 99 and the following chart, which together constitute the Central Dogmap.
FIGURE 99. The Central Dogmap. An analogy is established between two fundamental Tangled Hierarchies: that of molecular biology and that of mathematical logic.
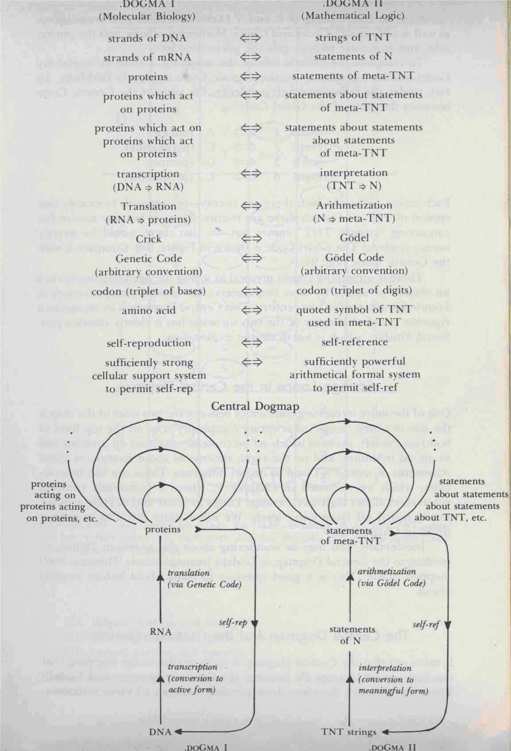
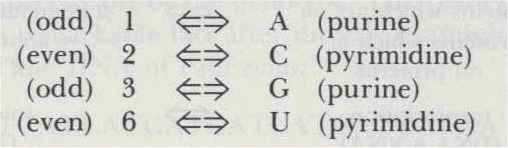
Note the base-pairing of A and T (Arithmetization and Translation), as well as of G
and C (Godel and Crick). Mathematical logic gets the purine side, and molecular biology gets the pyrimidine side.
To complete the esthetic side of this mapping, I chose to model my Godel-numbering scheme on the Genetic Code absolutely faithfully. In fact, under the following correspondence, the table of the Genetic Code becomes the table of the Godel Code: Each amino acid-of which there are twenty-corresponds to exactly one symbol of TNT-of which there are twenty. Thus, at last, my motive for concocting "austere TNT" comes out-so that there would be exactly twenty symbols! The Godel Code is shown in Figure 100.
Compare it with the Genetic Code (Fig. 94).
There is something almost mystical in seeing the deep sharing of such an abstract structure by these two esoteric, yet fundamental, advances in knowledge achieved in our century. This Central Dogmap is by no means a rigorous proof of identity of the two theories; but it clearly shows a profound kinship, which is worth deeper exploration.
Strange Loops in the Central Dogmap
One of the more interesting similarities between the two sides of the map is the way in which
"loops" of arbitrary complexity arise on the top level of both: on the left, proteins which act on proteins which act on proteins and so on, ad infinitum; and on the right, statements about statements about statements of meta-TNT and so on, ad infinitum. These are like heterarchies, which we discussed in Chapter V, where a sufficiently complex substratum allows high-level Strange Loops to occur and to cycle around, totally sealed off from lower levels. We will explore this idea in greater detail in Chapter XX.