The Numbers Behind NUMB3RS (8 page)
Read The Numbers Behind NUMB3RS Online
Authors: Keith Devlin

Kohonen networks have an architecture that incorporates a form of distance measurement, so that they essentially train themselves, without the need for any external feedback. Because they do not require feedback, there is no need for a large body of prior data; they train themselves by cycling repeatedly through the application data. Nevertheless, they function by adjusting connection weights, just like the other, more frequently used neural networks.
One advantage of neural networks over other data-mining systems is that they are much better able to handle the inevitable problem of missing data points that comes with any large body of human-gathered records.
CRIME DATA MINING USING NEURAL NETWORKS
Several commercial systems have been developed to help police solveâand on occasion even stopâcrimes.
One such is the Classification System for Serial Criminal Patterns (CSSCP), developed by computer scientists Tom Muscarello and Kamal Dahbur at DePaul University in Chicago. CSSCP sifts through all the case records available to it, assigning numerical values to different aspects of each crime, such as the kind of offence, the perpetrator's sex, height, and age, and the type of weapon or getaway vehicle used. From these figures it builds a crime description profile. A Kohonen-type neural network program then uses this to seek out crimes with similar profiles. If it finds a possible link between two crimes, CSSCP compares when and where they took place to find out whether the same criminals would have had enough time to travel from one crime scene to the other. In a laboratory trial of the system, using three years' worth of data on armed robbery, the system was able to spot ten times as many patterns as a team of experienced detectives with access to the same data.
Another such program is CATCH, which stands for Computer Aided Tracking and Characterization of Homicides. CATCH was developed by Pacific Northwest National Laboratory for the National Institute of Justice and the Washington State Attorney General's Office. It is meant to help law enforcement officials determine connections and relationships in data from ongoing investigations and solved cases. CATCH was built around Washington state's Homicide Investigation Tracking system, which contains the details of 7,000 murders and 6,000 sexual assault cases in the Northwest. CATCH uses a Kohonen-style neural network to cluster crimes through the use of parameters such as modus operandi and signature characteristics of the offenders, allowing analysts to compare one case with similar cases in the database. The system learns about an existing crime, the location of the crime, and the particular characteristics of the offense. The program is subdivided into different tools, each of which places an emphasis on a certain characteristic or group of characteristics. This allows the user to remove certain characteristics which humans determine are unrelated.
Then there is the current particular focus on terrorism. According to the cover story in
BusinessWeek
on August 8, 2005: “Since September 11 more than 3,000 Al Qaeda operatives have been nabbed, and some 100 terrorist attacks have been blocked worldwide, according to the FBI. Details on how all this was pulled off are hush-hush. But no doubt two keys were electronic snoopingâusing the secret Echelon networkâand computer data mining.”
Echelon is the global eavesdropping system run by the National Security Agency (NSA) and its counterparts in Canada, Britain, Australia, and New Zealand. The NSA's supercomputers sift through the flood of data gathered by Echelon to spot clues to terrorism planning. Documents the system judges to merit attention go to human translators and analysts, and the rest is dumped. Given the amount of data involved, it's hardly surprising that the system sometimes outperforms the human analysts, generating important information too quickly for humans to examine. For example, two Arabic messages collected on September 10, 2001, hinting of a major event to occur on the next day, were not translated until September 12. (Since that blackest of black days, knowledgeable sources claim that the translation delay has diminished to about twelve hours. The goal, of course, is near-real-time analysis.)
The ultimate goal is the development of data-mining systems that can look through multiple databases and spot correlations that warn of plots being hatched. The Terrorism Information Awareness (TIA) project was supposed to do that, but Congress killed it in 2003 because of privacy concerns. In addition to inspecting multiple commercial and government databases, TIA was designed to spin out its own terrorist scenariosâsuch as an attack on New York Harborâand then determine effective means to uncover and blunt the plots. For instance, it might have searched customer lists of diving schools and firms that rent scuba gear, and then looked for similar names on visa applications or airline passenger lists.
I KNOW THAT FACE
Facial recognition systems often make use of neural networks. Current recognition systems reduce the human face to a sequence of numbers (sometimes called a “face print” or a “feature vector”). These numbers are distance measurements at and between pairs of eighty so-called nodal points, key features of the face such as the centers of the eyes, the depths of the eye sockets, cheekbones, jaw line, chin, the width of the nose, and the tip of the nose. (See figure 3.) Using fast computers, it is possible to compute the face print of a target individual and compare it to the face prints in a database within a few seconds. The comparison cannot be exact, since the angle of observation of the target will be different from that of each photograph used to generate the face print in the database, although this effect can be overcome in part by means of some elementary trigonometric calculations. But this is the kind of “closest match” comparison task that neural networks can handle well.
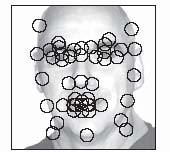
Figure 3. Many facial recognition systems are based on measurements of and between key locations on the face called nodal points.
One advantage of facial recognition using neural network comparisons of face prints is that it is not affected by surface changes such as wearing a hat, growing or removing a beard, or aging. The first organizations to make extensive use of facial recognition systems were the casinos, who used them to monitor players known to be cheaters. Airport immigration is a more recent, and rapidly growing application of the same technology.
While present-day facial recognition systems are nowhere near as reliable as they are depicted in movies and in television dramasâparticularly in the case of recognizing a face in a crowd, which remains a difficult challengeâthe technology is already useful in certain situations, and promises to increase in accuracy over the next few years.
The reason that facial recognition is of some use in casinos and airport immigration desks is that at those locations the target can be photographed alone, full face on, against a neutral background. But even then, there are difficulties. For example, in 2005, Germany started issuing biometric passports, but problems arose immediately due to people smiling. The German authorities had to issue guidelines warning that people “must have a neutral facial expression and look straight at the camera.”
On the other hand, there are success stories. On December 25, 2004, the
Los Angeles Times
reported a police stop west of downtown Los Angeles, where police who were testing a new portable facial recognition system questioned a pair of suspects. One of the officers pointed the system, a hand-held computer with a camera attached, toward one of the two men. Facial recognition software in the device compared the image with those in a database that included photos of recent fugitives, as well as just over a hundred members of two notorious street gangs. Within seconds, the screen had displayed a gallery of nine faces with contours similar to the suspect's. The computer concluded that one of those images was the closest match, with a 94 percent probability of accuracy.
THE CASE OF THE SUSPICIOUS CONFERENCE CALLS
Detecting telephone fraud is another important application of neural networks.
Dr. Colleen McCue was, for many years, the program manager for the crime analysis unit at the Richmond Police Department in Richmond, Virginia, where she pioneered the use of data-mining techniques in law enforcement. In her book
Data Mining and Predictive Analysis
, she describes one particular project she worked on that illustrates the many steps that must often be gone through in order to extract useful information from the available data. In this case, a Kohonen neural net was used to identify clusters in the data, but as Dr. McCue explains, there were many other steps in the analysis, most of which had to be done by hand. Just as in regular police detective work, where far more time is spent on routine “slogging” and attention to details than on the more glamorous and exciting parts dramatized in movies and on TV, so too with data mining. Labor-intensive manipulation and preparation of the data by humans generally accounts for a higher percentage of the project time than the high-tech implementation of sophisticated mathematics. (This is, of course, not to imply that the mathematics is not important; indeed, it is often crucial. But much preparatory work usually needs to be done before the mathematics can be applied.)
The case McCue describes involves the establishment of a fraudulent telephone account that was used to conduct a series of international telephone conferences. The police investigation began when a telephone conference call service company sent them a thirty-seven-page conference call invoice that had gone unpaid. Many of the international conference calls listed on the invoice lasted for three hours or more. The conference call company had discovered that the information used to open the account was fraudulent. Their investigation led them to suspect that the conference calls had been used in the course of a criminal enterprise, but they had nothing concrete to go on to identify the perpetrators. McCue and her colleagues set to work to see if a data-mining analysis of the conference calls could provide clues to their identities.
The first step in the analysis was to obtain an electronic copy of the telephone bill in easily processed text format. With telephone records, this is fairly easy to do these days, but as data-mining experts the world over will attest, in many other kinds of cases a great deal of time and effort has to be expended at the outset in re-keying data as well as double-checking the keyed data against the hard-copy original.
The next stage was to remove from the invoice document all of the information not directly pertinent to the analysis, such as headers, information about payment procedures, and so forth. The resulting document included the conference call ID that the conference service issued for each call, the telephone numbers of the participants, and the dates and durations of the calls. Fewer than 5 percent of entries had a customer name, and although the analysts assumed those were fraudulent, they nevertheless kept them in case they turned out to be useful for additional linking.
The document was then formatted into a structured form amenable to statistical analysis. In particular, the area codes were separated from the other information, since they enabled linking based on area locations, and likewise the first three digits of the actual phone number were coded separately, since they too link to more specific location information. Dates were enhanced by adding in the days of the week, in case a pattern emerged.
At this point, the document contained 2,017 call entries. However, an initial visual check through the data showed that on several occasions a single individual had dialed in to a conference more than once. Often most of the calls were of short duration, less than a minute, with just one lasting much longer. The most likely explanation was that the individuals concerned had difficulty connecting to the conference or maintaining a connection. Accordingly, these duplications were removed. That left a total of 1,047 calls.
At this point, the data was submitted to a Kohonen-style neural network for analysis. The network revealed three clusters of similar calls, based on the day of the month that the call took place and the number of participants involved in a particular call.
Further analysis of the calls within the three clusters suggested the possibility that the shorter calls placed early in the month involved the leaders, and that the calls at the end of the month involved the whole group. Unfortunately for the police (and for the telephone company whose bill was not paid), at around that time the gang ceased their activity, so there was no opportunity to take the investigation any further. The analysts assumed that the sudden cessation was preplanned, since the gang organizers knew that when the bill went unpaid, the authorities would begin an investigation.